伪分布式环境搭建实验报告

¶step1 虚拟机安装与操作

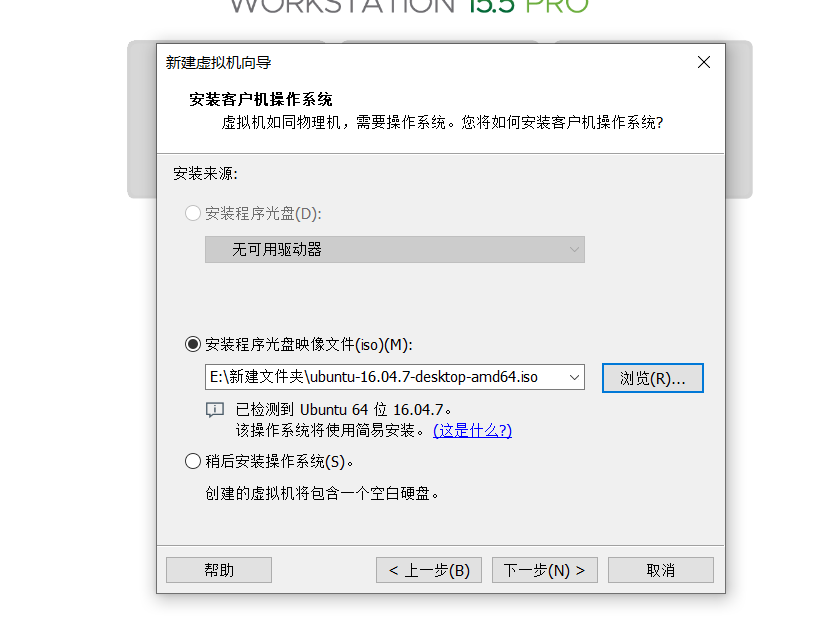
新建虚拟机选择ubbuntu16镜像,然后一直下一步即可
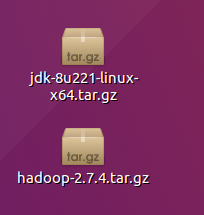
由于之前安装了VMtools,所以接下来直接将hadoop和jdk的压缩包复制粘贴进虚拟机
¶step2 环境搭建
¶java环境配置
1 | sudo mkdir /usr/java |
1 | sudo vim ~/.bashrc |
在最后一行加上

1 | source ~/.bashrc |
1 | sudo vim /etc/profile |
在最后一行加上

1 | sudo vim /etc/environment |
在最后一行加上

1 | source /etc/environment |
1 | java -version |

¶ssh-server配置
安装并启动ssh-server
1 | sudo apt-get install openssh-server |
生成RSA
1 | ssh-keygen -t rsa |
关闭防火墙
1 | sudo ufw disable |
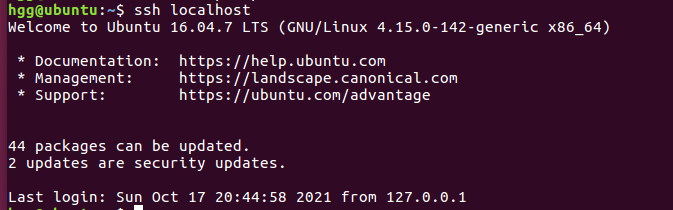
链接测试
¶安装hadoop
解压
1 | sudo tar zxvf hadoop-2.7.4.tar.gz -C /usr/local |
配置
1 | sudo vim ~/.bashrc |
在最后加上
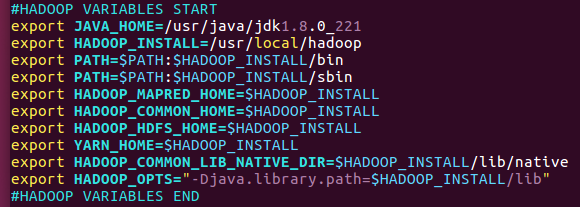
1 | source ~/.bashrc |
1 | sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh |
在最后加上

1 | sudo vim /usr/local/hadoop/etc/hadoop/yarn-env.sh |
在最后加上

1 | sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml |
在configuration标签中加入
1 | <configuration> |
1 | sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml |
在configuration标签中加入
1 | <configuration> |
1 | sudo vim /usr/local/hadoop/etc/hadoop/yarn-site.xml |
在configuration标签中加入
1 | <configuration> |
重启后输入
1 | hadoop version |
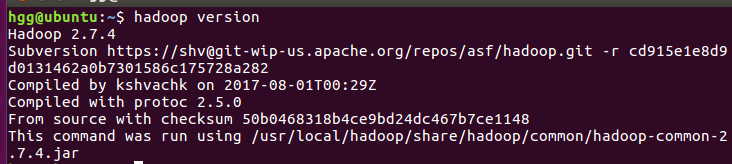
启动
1 | hdfs namenode -format |
访问本地的8088,和50070端口
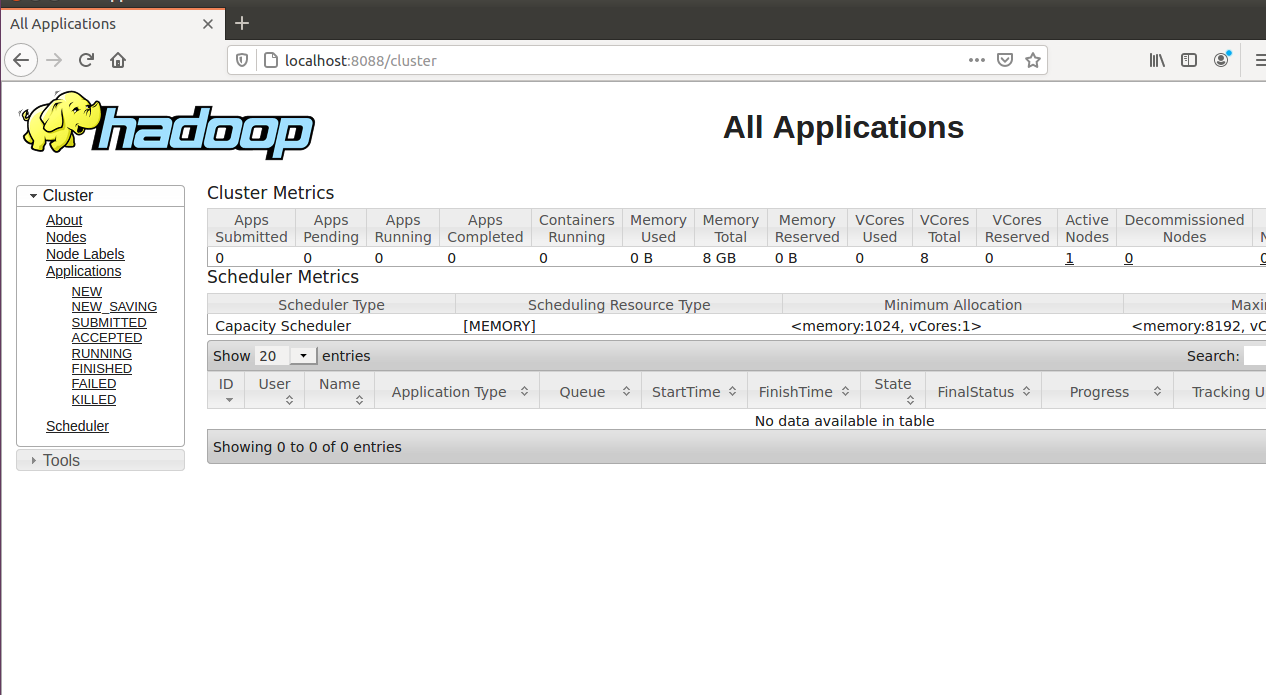
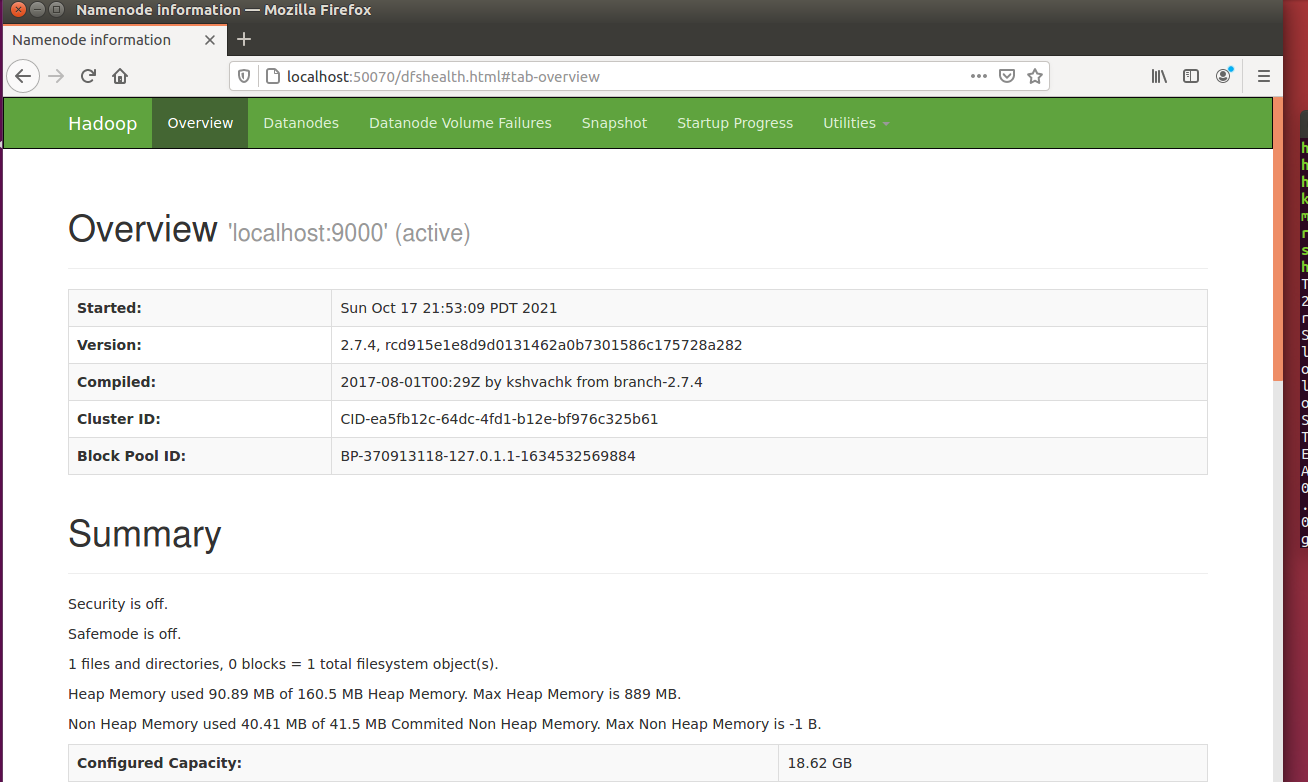
¶Step3 平台操作
新建目录
1 | hadoop fs -mkdir /tmp/input |
上传本地文件
1 | hadoop fs -put exp.py /tmp/input |
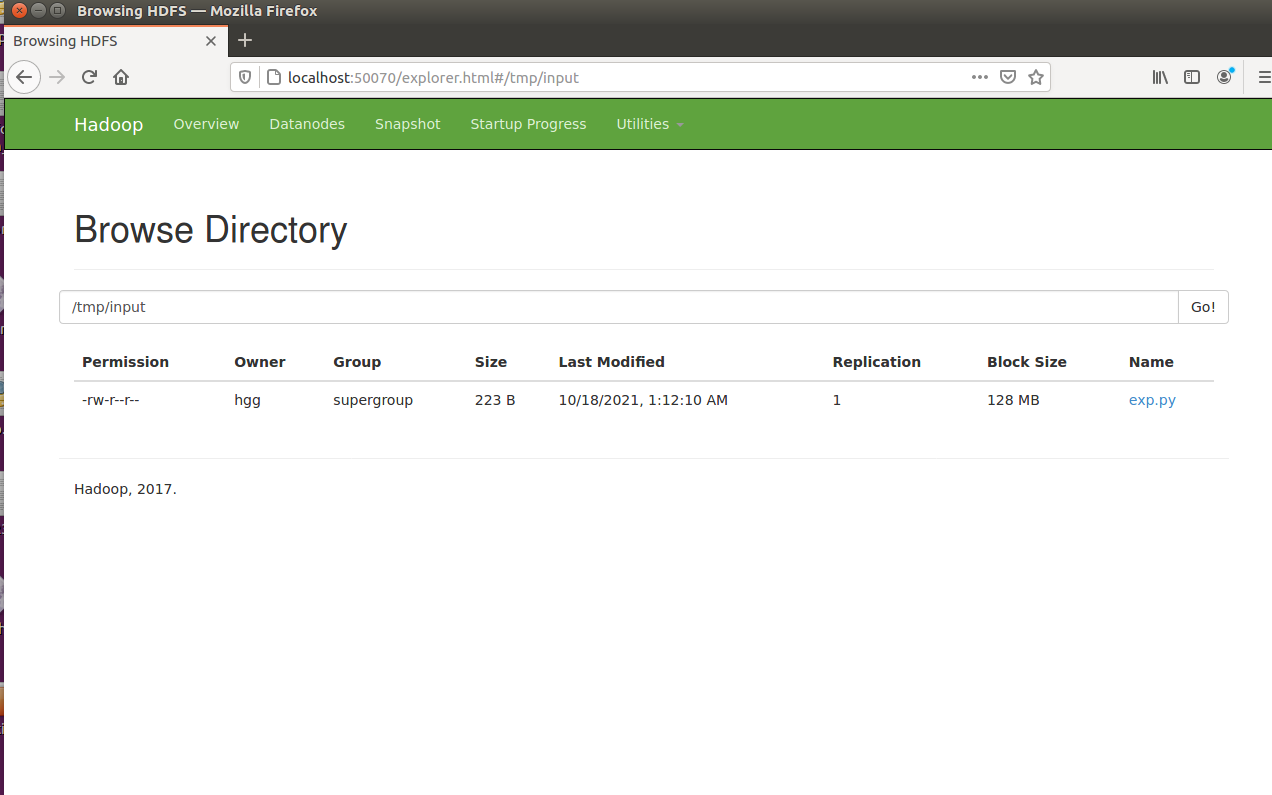
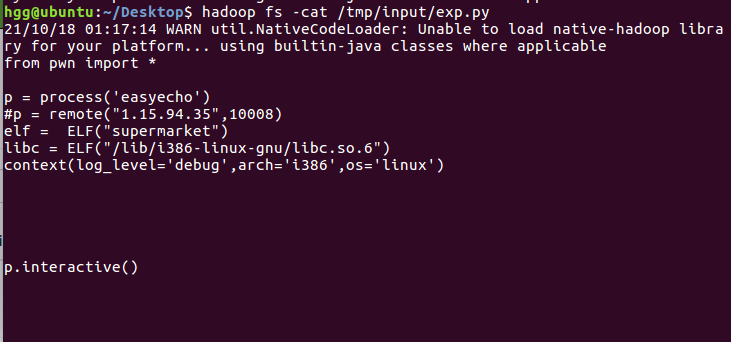
查看
1 | hadoop fs -cat /tmp/input/exp.py |
¶参考
https://blog.csdn.net/kh896424665/article/details/78765175
https://www.cnblogs.com/biehongli/p/7026809.html